「dサーベイ世論調査」の効用/松本 正生
「dサーベイ世論調査」の効用
松本 正生(社会調査研究センター)
それでは、私から「dサーベイ世論調査の効用」というタイトルでご報告してまいります。よろしくお願いします。
dサーベイの場合、ネット調査というくくりに入るのかとは思います。ただ、ネット調査とかインターネット調査といった場合に非常に定義や種類が多くて、若干錯綜して捉えられているので、最初に少し整理をしておきたいと思います。
スライド②をご覧ください。

スライド②
インターネット調査の類型をまとめてみました。表の一番上、「モニター型」と表現しましたけれども、調査会社さんが募り、そこにモニター登録したボランティアパネルの方たちを対象に行っている、これが最も一般的かと思います。この場合はやはり、調査会社さんごとの回答者、対象者の特性というのが付随する。また、お1人でいろいろな調査会社さんのモニターに登録されている方、すなわち重複というようなことがあったりするのではないかと思います。次に、最近多いの手法を「アクセス型」と表現しました。適確なネーミングかどうかわかりませんが、いわゆるポータルサイト上に設定された質問に回答者がアクセスして答える、こういうやり方ですので、どういう方たちが回答されるかという構成については、やってみないと分からないというようなことだと思います。研究者の方たちが、いわゆる「クラウド型」というような形で調査をやられるものも、この類型に属するのではないかと思います。
我々の「dサーベイ」というのは、これらとはタイプが全く違いまして、NTTドコモさんのユーザー―に限りませんけれども、ほかのキャリアさんのユーザーも含めて―を中心として、現在約6,800万人(2024年9月現在は7,014万人)の有権者の方たちを母集団としている。それから、選定方法、いわゆるサンプリングですけれども、お1人が1つのアカウントを持っていらっしゃるので、個人単位のランダムサンプリングという形で調査が行える。そして、これからご覧に入れますけれども、男女・年齢・地域など、デモグラフィックの要素というものが人口構成の縮図になっているという特性があるので、通常のネット調査とはカテゴリーが違うのかなとは思っています。スライド③(dサーベイとは)でもう一度整理をしますと、ここに書きましたように、高齢者を中心に日々増えているので、現在はさらにプラスアルファだと思いますけれども、6,800万人強のシングルフレームという、ドコモのユーザーさんを中心とする非常に大きなサブスクライバーをシングルフレーム、単一母集団として、1人に1つのアカウントなので個人単位の無作為抽出が可能である。すなわち、従来型の―既存のと言ったら失礼なのかもしれないですけれども―インターネット調査とは全く次元が異なります。我々のdサーベイに関しては、今、ネット調査というラベルが貼られているのですけれども、いつまでそれが続くのかなと、注視していこうと思っています。

スライド③
スライド④(dサーベイの特性)でdサーベイの特徴をさらっとおさらいしておくと、当然これは「目で見る調査」という形になる。電話調査のような「耳で聞く調査」ではないので、質問と選択肢の一覧性がある。それから、選挙のときなど、同一政党から複数の候補者が出たときの、初頭バイアスとよく言われますけれども、こういうことを回避できる。さらに、クエスチョネアの選択肢をたくさん設定できて、一覧性があるということ。

スライド④
もう一つは、調査員が介在しないということで、回答者ご本人が直接答えるので、実査条件の均質性が確保でき、いわゆる観測刺激と言われるようなものが軽減される。それから、自記式ですので自由回答質問の設定が可能です。調査員、オペレーターが介在しないというのは、我々としては非常にプラスのポイントであると捉えております。この点はまた後でちょっと触れます。
本題に入りますけれども、dサーベイの精度というのを2つに分けて考えてみたいと思います。スライド⑤(dサーベイの精度①)

スライド⑤
まずは、母集団の品質というものを表示できるというのが非常に大きな特徴かなと思います。これからご覧に入れるように、男女・年齢・地域などの人口構成というものがきちんと確定できて表示できるということが特徴です。今、世論調査と言われているRDD=電話調査というのは、母集団のグロスというのは何となく分かっても、構成というのが果たして明示できるのかという疑問を持っております。 スライド⑥(dサーベイの精度②)をご覧ください。
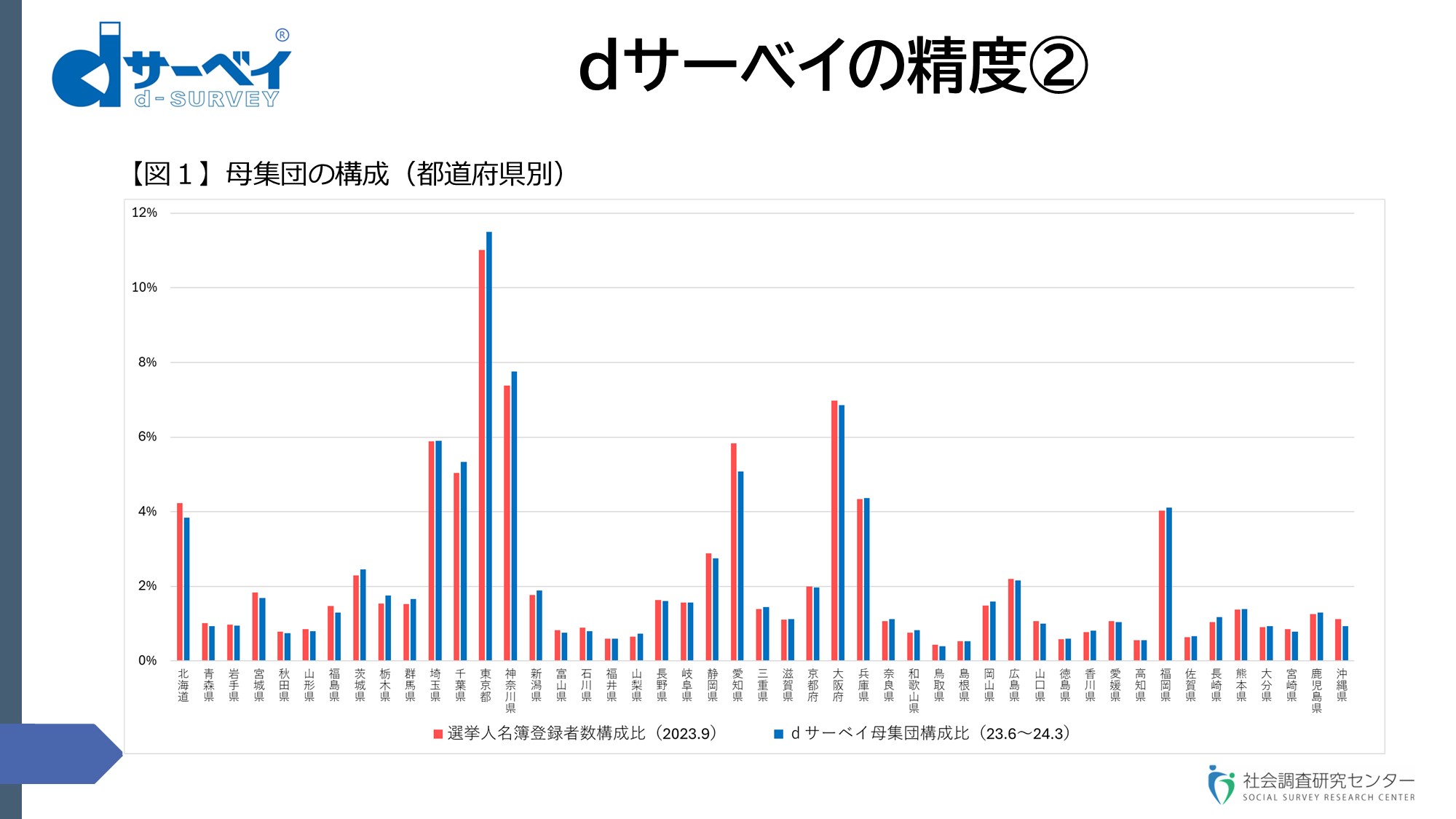
スライド⑥
dサーベイ調査の母集団の構成の1つ目のデータです。これは都道府県別の人口構成比【図1】。選挙人名簿に基づく全国の有権者数の都道府県別の構成比で、赤色のほうです。それに対して青色のグラフが、私どもの今の6,800万人強の母集団の都道府県別の構成です。これが各都道府県の構成比率と近似しているということがお分かりになると思います。RDDの電話調査に関しては、今、携帯と固定のミックスで実施しているわけですけれども、携帯電話のほうは、ご存じのとおり地域情報が番号にない。固定電話の場合は、世帯単位ですので、個人単位での構成データというものがこういう形で存在するのか、確定しているのかということも大きな違いかなと思います。
地域の次はスライド⑦(dサーベイの精度③)です。
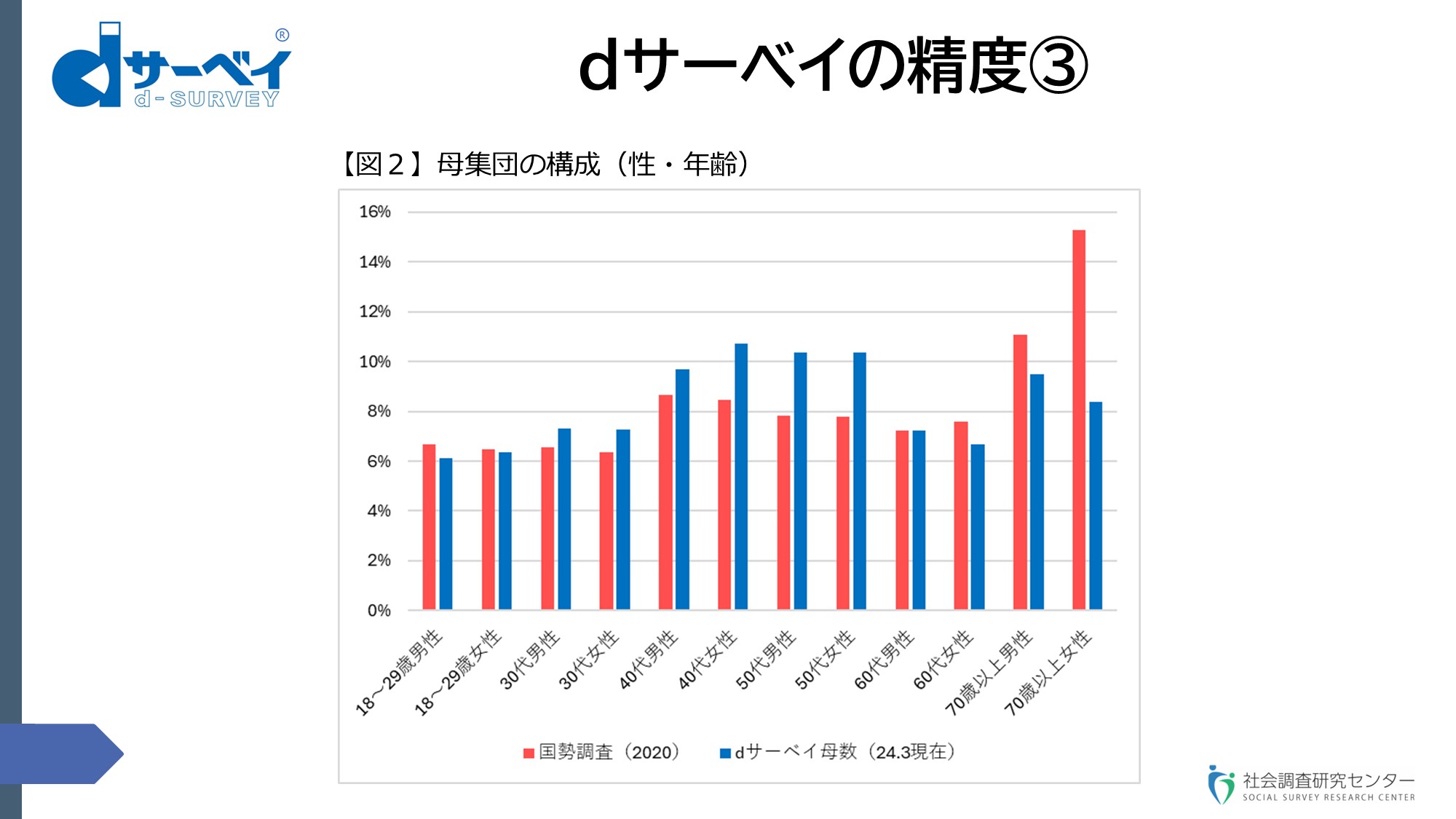
スライド⑦
これが性・年齢別の人口構成比です【図2】。2020年の国勢調査における性・年齢別の構成が赤です。私どもの6,800万人強の母集団、dサーベイの母集団の性・年齢別の構成比が青色です。私どもの母集団の一つの特徴は、40代、50代というのがボリュームゾーンです。ですから、この構成比が実際よりも多い。もう一つは、70歳以上の女性の構成比が実際の人口構成よりも非常に小さい。これが私どもの母集団の品質になります。いずれにせよ、母集団の品質というのを表示できる、確定できるということが我々の特性だと思います。
再々申し上げますけれども、電話のRDD調査の場合は、グロスだけは何となく分かるのですけれども、固定、携帯とも母集団に関するこういう構成データというものは寡聞にして見たことがないので、どうなのだろうか。携帯電話の場合は、よく言われるように、同一人が複数所有しているということが言われるわけですけれども、そもそもそれがどの程度なのかというようなことに関してもよくわからない。もう一つあえて申し上げると、世論調査というと、母集団に関してはすぐカバレッジということが問題になるのですけれども、カバレッジを問題にするのであれば、本来は構成を含めて議論され、表示され、確定されるべきではないかとも思っています。これが母集団に関しての品質です。
次はスライド⑧(dサーベイの精度④)です。

スライド⑧
もちろん回答者に関しても品質が表示できる。男女や年齢だけではなくて地域別でもということで、1つ例をご覧に入れると、スライド⑨(dサーベイの精度⑤)になります。
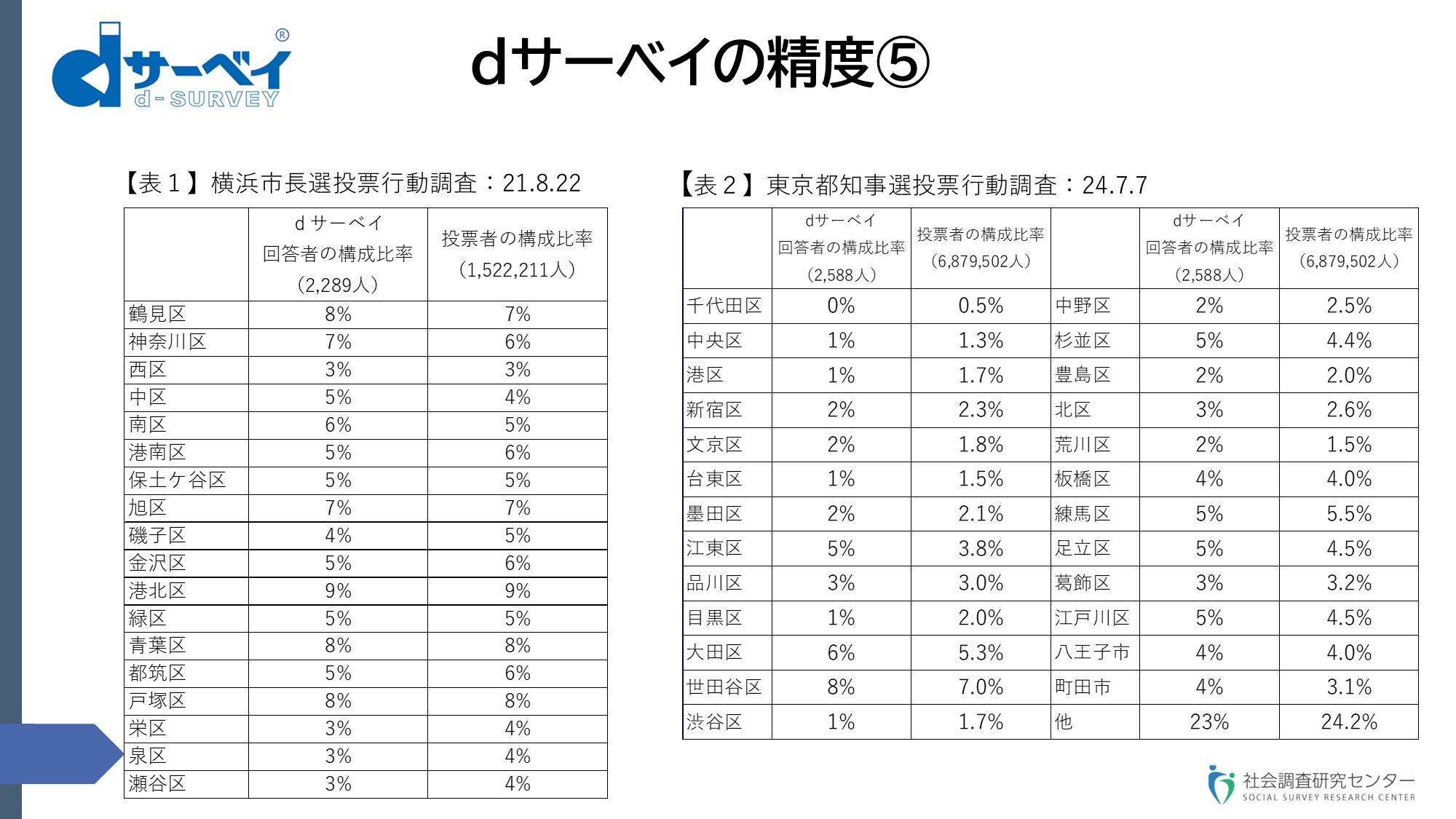
スライド⑨
これは私どもは投票行動調査と呼んでいますが、投票日当日に「どなたに投票しましたか」ということをお聞きした結果をフォローしています。いわゆる出口調査に相当します。投票に行かれた方に投票所の出口で聞く出口調査、exit pollに相当します。ただ、私どもの投票行動調査は、投票日当日に聞くわけですけれども、期日前投票に関しても捕捉できるという特徴を持っています。
左側の【表1】が2021年8月の横浜市長選での投票行動調査の結果です。それから、右側の【表2】が、つい最近行われた、7月7日の東京都知事選の投票行動調査の結果です。実際の候補者ごとの結果は、後で平田のほうからの報告があるので、そちらでご確認いただきたいと思いますが、横浜、東京とも実際の結果にぴったりでした。最下位の方まで、言い方は失礼かもしれませんけれども、俗に言う泡沫候補の方までぴったり実際の結果と符合したというパフォーマンスでした。
要は、一つの特徴として、私どもの調査の回答者が、実際に投票した投票者全体の縮図になっている。これが精度を担保していると感じています。横浜市長選で言えば、152万人の投票者全体のうち、18区ある各区ごとの投票者の市全体に占める構成比というのが、実際の我々のdサーベイの18区ごとの構成比とほぼ近似している。直近の東京都の知事選に関しても、全部で688万人が投票しましたが、23区と、人口の多い八王子市と町田市とその他に分けて全体に占めるそれぞれの比率をまとめました。私どもの調査の回答者の区別の構成比というのがほぼ符合するということで、回答者が投票者全体の縮図となっているということがお分かりいただけると思います。
私どもは、これだけではなくて、2021年の衆院選においては289選挙区全てで、そして2022年の参院選など各種の選挙調査で、精度を実証してきました。そして、満を持して2022年10月からdサーベイによる全国世論調査を開始しました(スライド⑩)。これは月例で、回答者は大体2,000人規模の全国調査を毎月行っています。そのパフォーマンスを、まずは回答者の構成というところからご覧に入れたいと思います。

スライド⑩
スライド⑪(dサーベイ世論調査のパフォーマンス②)先ほど皆様に見ていただいた【図2】に対応するのですけれども、国勢調査における性・年齢別の構成比と私どものdサーベイ全国世論調査の回答者の構成比を比較したものです【図3】。
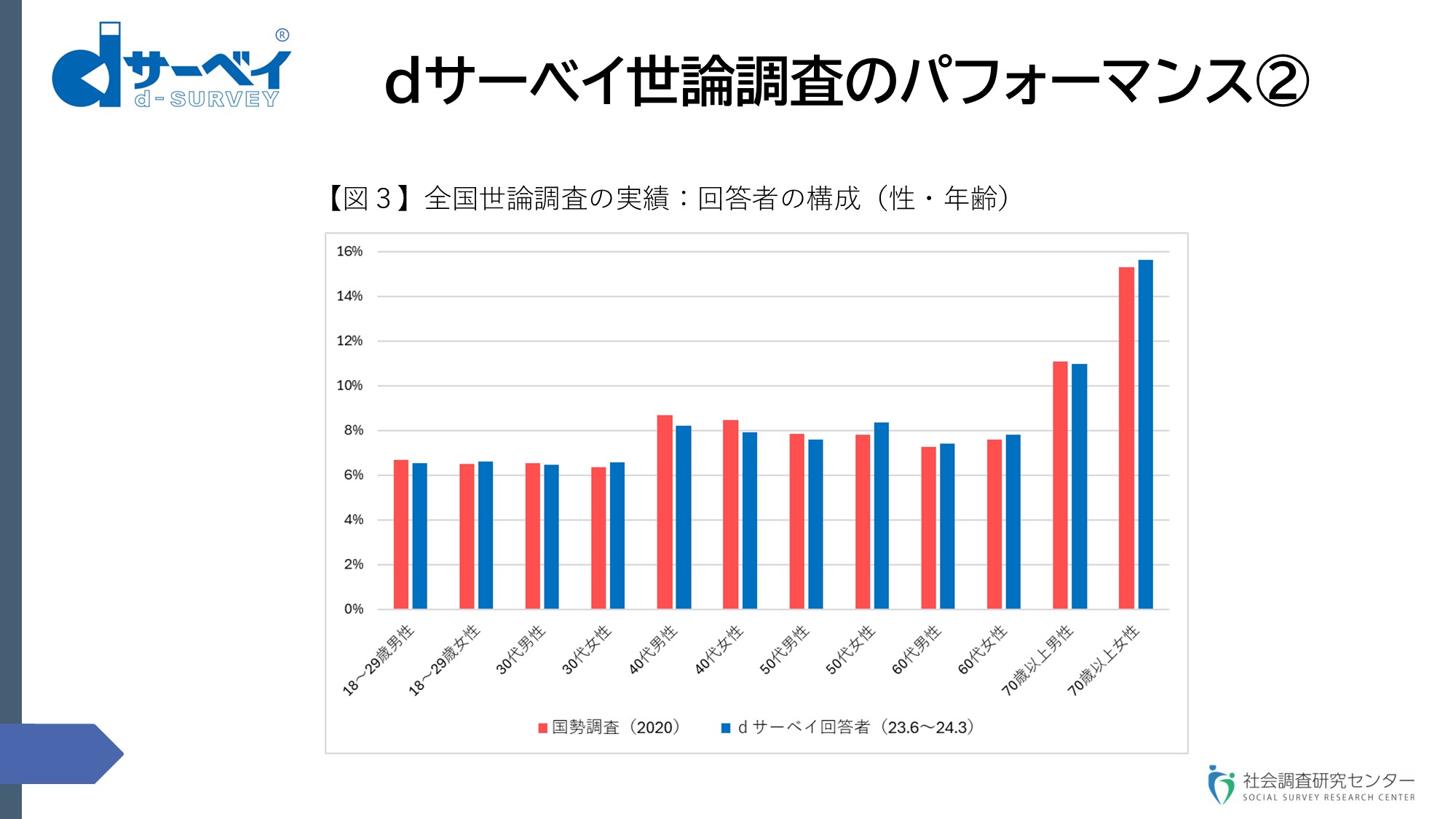
スライド⑪
先ほどご覧に入れたように、40代、50代のところが、私どもの場合、人口構成より多かったのですけれども、ここがほぼ整合している。それから、一番の特徴であった70代以上の女性も人口構成とほぼ近似して、【図2】でご覧に入れた母集団の偏りが克服できています。次の報告でありますけれども、配信設計モデルというのを確立しました。すなわち、性・年代別の構成というものの母集団の偏りのデータが1つ目の基本データ。それから、選挙調査をたくさん重ねる中で、性・年代ごとの回収実績のデータというものも蓄積して、この2つの指標を統合して配信数を設計するというモデルを確立して、精度を上げたということです。それに従って全国世論調査を実施すると、回答者が安定的に確保できる。
配信設計とはもちろん、いわゆる割当てではありません。各年代ごとに取る数を事前に割り当てて追跡するという方法ではありません。あるいは、RDD調査でオペレーターさんに特定の性・年代だけ、例えば20代の男性だけ集中的に充足させるというような、そういう酷なやり方でもありません。もう一度言うと、事後的な補正をせずに、任意回答で人口構成に整合するという形で回答者を確保できるということです。
この辺はあまり強調したくはないのですが、私どもも、電話によるいわゆる世論調査、全国世論調査というのを毎月受託して実施しています。スライド⑫(dサーベイ世論調査と電話世論調査①)は、そのデータです【図4】。
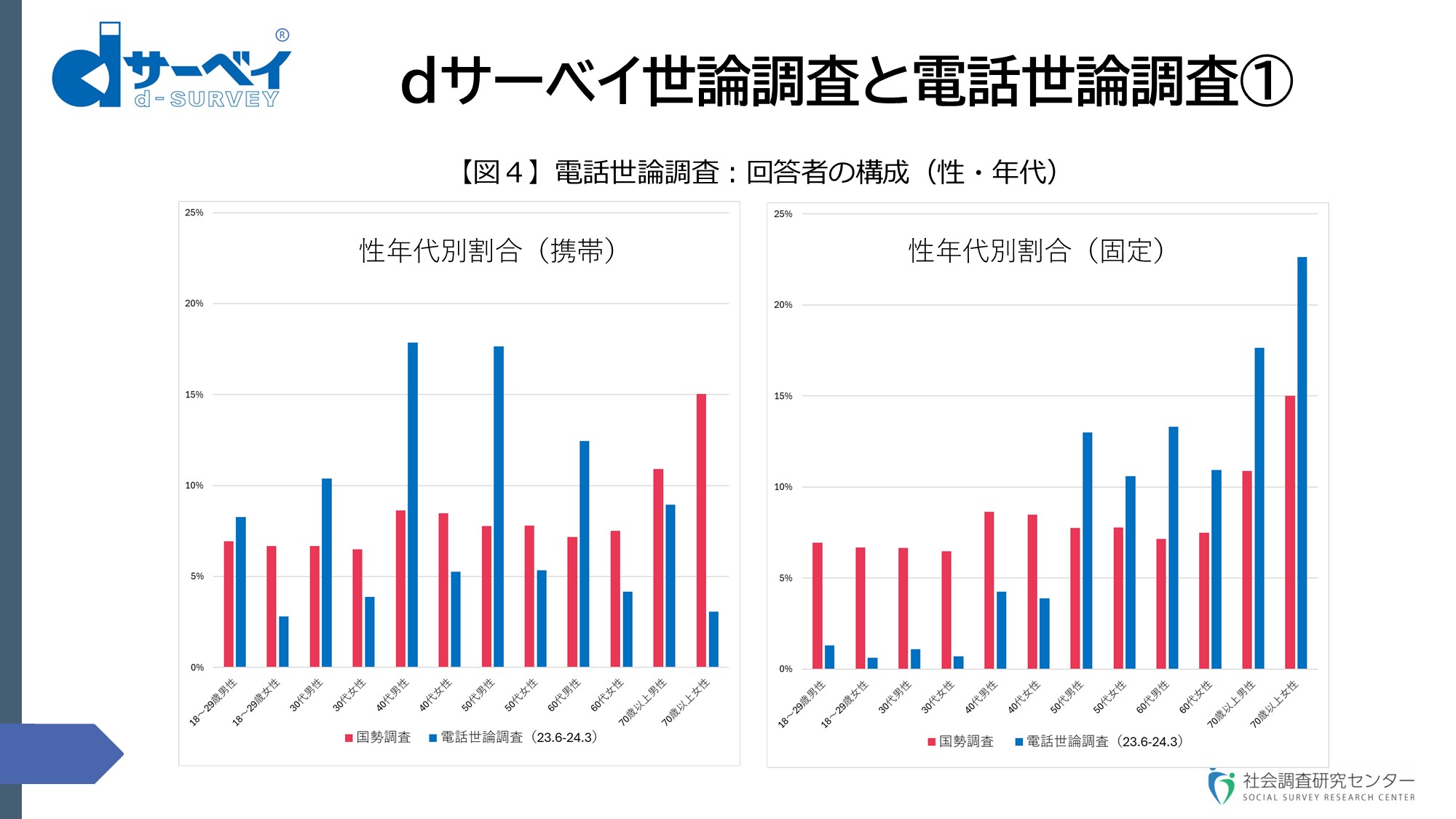
スライド⑫
左側は携帯電話の回答者の性・年齢別構成比です。やはりこういう形で、人口構成に比べてかなり偏りがあります。右側が固定電話調査での回答者の構成比です。固定電話ですので、こういう形にならざるを得ない。
ということで、現在はどの社もミックス、すなわち携帯と固定をコンバインして結果を出しているわけです。しかしながら、ミックスしても、なかなかこの偏りというのが相殺されない。
スライド⑬(dサーベイ世論調査と電話世論調査②)をご覧ください【図5】。
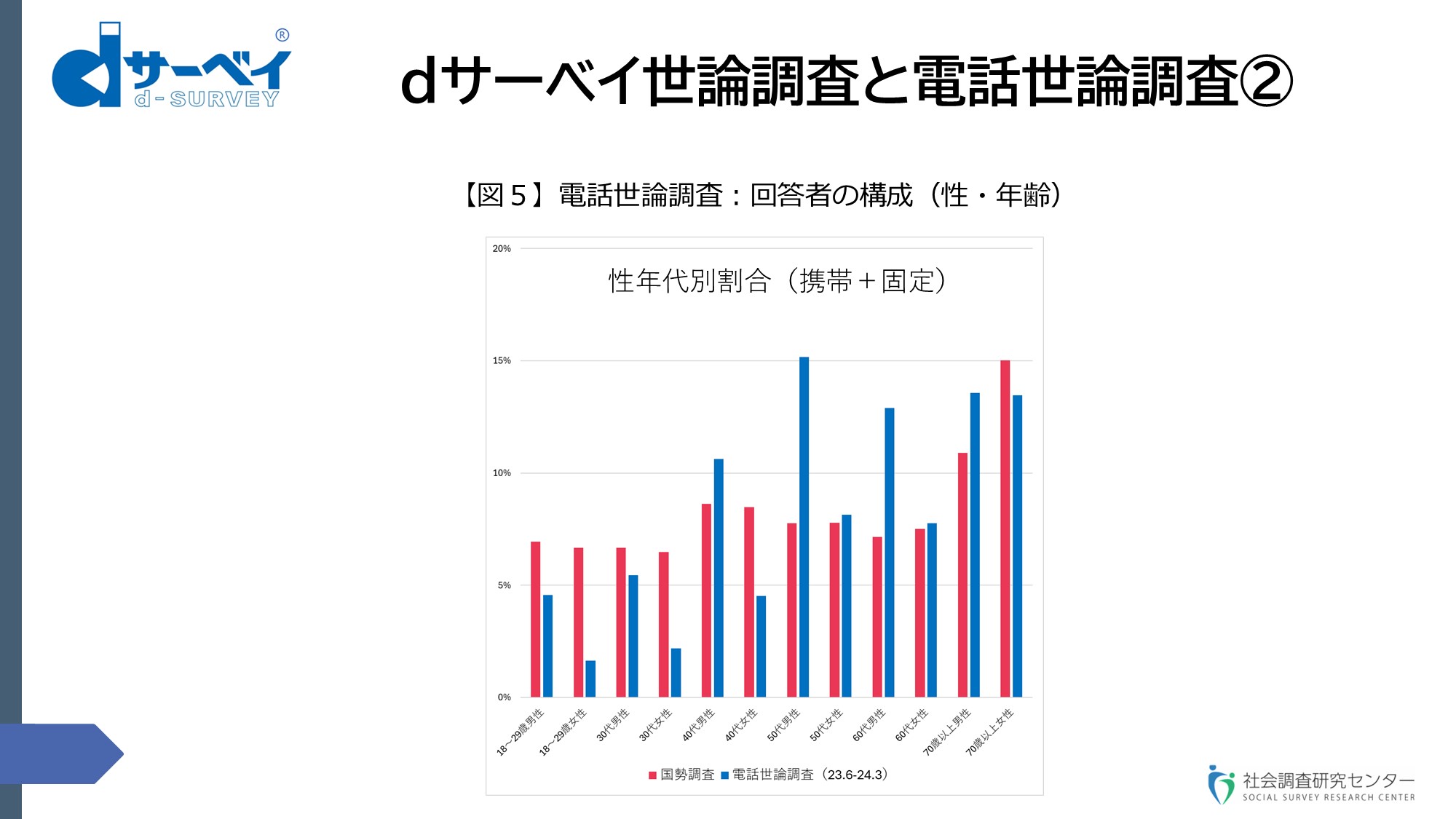
スライド⑬
ということは、事後補正せざるを得ないというのが残念ながら現状で、RDDをおやりの方はよくご存じだと思います。携帯電話の場合、毎回の偏りが一定であれば、それなりの意味はあると思いますけれども、非常に不安定になると、今度は補正の意味が軽減されるということもあるのではないかと思います。これが回答者の構成に関しての比較データです。
続いて、今度は回答結果のほうに行きたいと思います(スライド⑭)。

スライド⑭
dサーベイ世論調査で全国調査をやっているので、電話世論調査の回答結果と比較するとなると、内閣支持率のデータというのが一番注目されて、皆さん気にされると思うので、ご覧に入れます。
スライド⑮(dサーベイ世論調査と電話世論調査③)です。
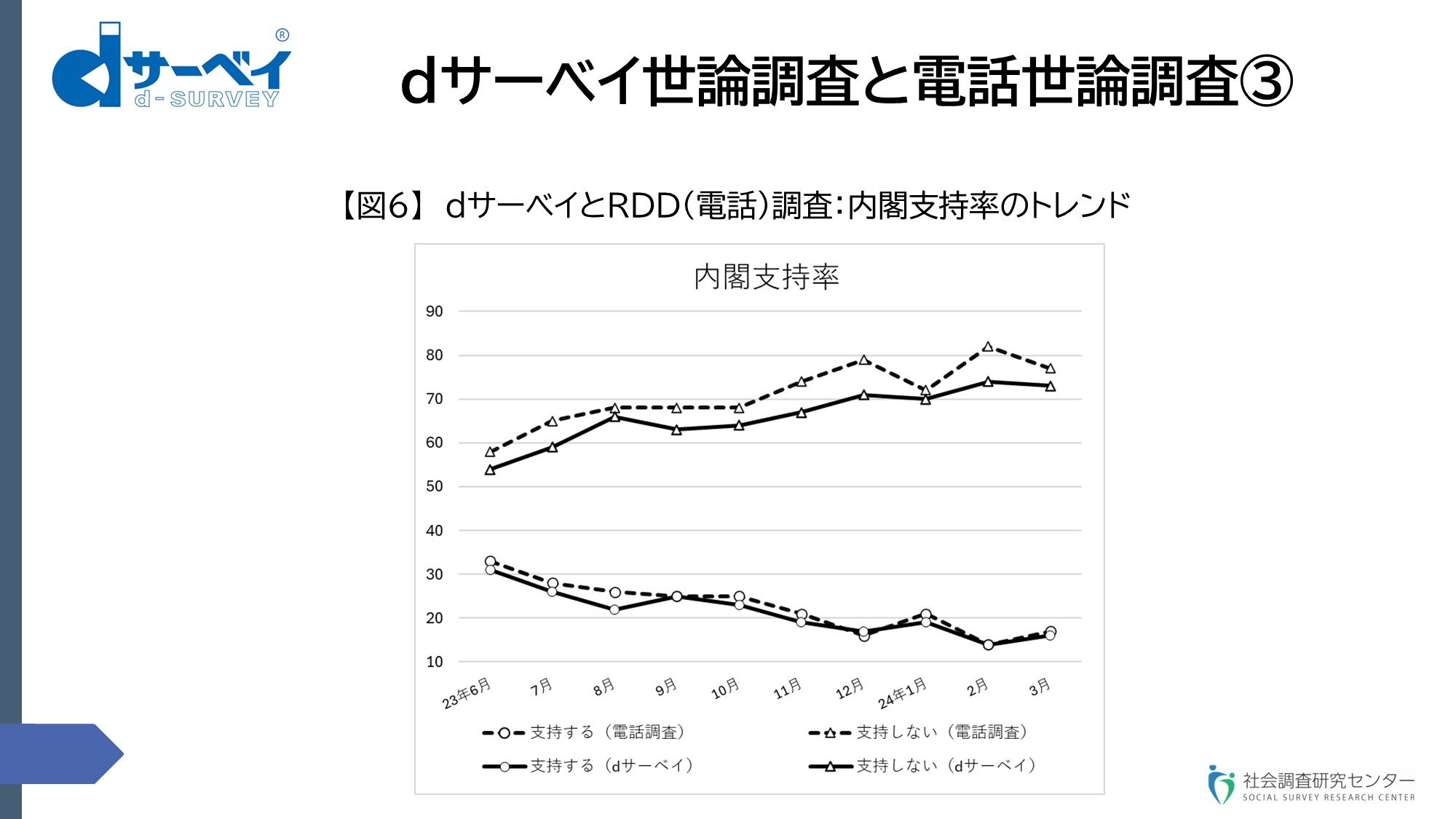
スライド⑮
実線がdサーベイの岸田内閣支持率(〇印)と不支持率(△印)です。点線が電話世論調査の同支持率(〇印)、不支持率(△印)です。こんな形状になっています【図6】。
実は、内閣支持率の絶対値とかトレンドを、dサーベイとRDDを比較すること自体、私はあまり意味がないと思います。なぜかというと、そもそも世論調査の結果が正しいかどうかは分からないわけですよね。そうなると、その信憑性を担保しているのは何かというと、世論調査と同じ方法で行われている選挙情勢調査の精度というものが、世論調査結果の信憑性を担保する唯一の基準であるということだと思います。だから、選挙の調査こそが大事であるというのが前提条件だと思います。もちろんそれは、同じ方法で実施するということが大事な要件になりますので、残念ながら、今や世論調査と選挙情勢調査というのは異なる手法を各社とも用いるようになりました。例えば世論調査は電話調査で、それに対して選挙調査はネット調査でというようなこと。あるいは、同じRDDの電話調査を使うとしても、世論調査のほうは固定と携帯のミックス、それに対して選挙調査は固定電話オンリー。あるいは、世論調査のほうはオペレーター方式で、選挙調査のほうはオートコールでみたいな、こういう違いが最近出てきたわけです。
では、信憑性のよりどころは何かということになるのですけれども、最近見ていると、それは要するに他社の内閣支持率みたいな状況を呈しています。これは、言ってみれば、みんなと同じかどうかということにすぎないわけですよね。しかも、はっきり言えば、調査するメディアの側の内向きの理屈にすぎないわけです。そんな内向きの理屈というのがなぜ通用しているのかと考えると、それは政治家から文句が来ないということだと思います、失礼ながら。どこを向いて調査をしているのかということが問われるのではないかと私は思います。
では、dサーベイの結果を何と比較するべきなのかといえば、今、世論調査らしい世論調査は郵送調査しかないわけで、郵送調査というのは、当然母集団が確定できて、代表性というのが確保されている。それから、回答者の品質も表示できる。ですから、dサーベイ世論調査と郵送世論調査の、ほぼ同じような時期に行った同一質問で、同一の選択肢で実施した結果を比較してみました。都合がいいことに、dサーベイも郵送世論調査も同じ自記式で、調査員やオペレーターが介在しない、「目で見る」調査という比較可能性を担保しております。
スライド⑯(dサーベイ世論調査と郵送世論調査①)をご覧ください。
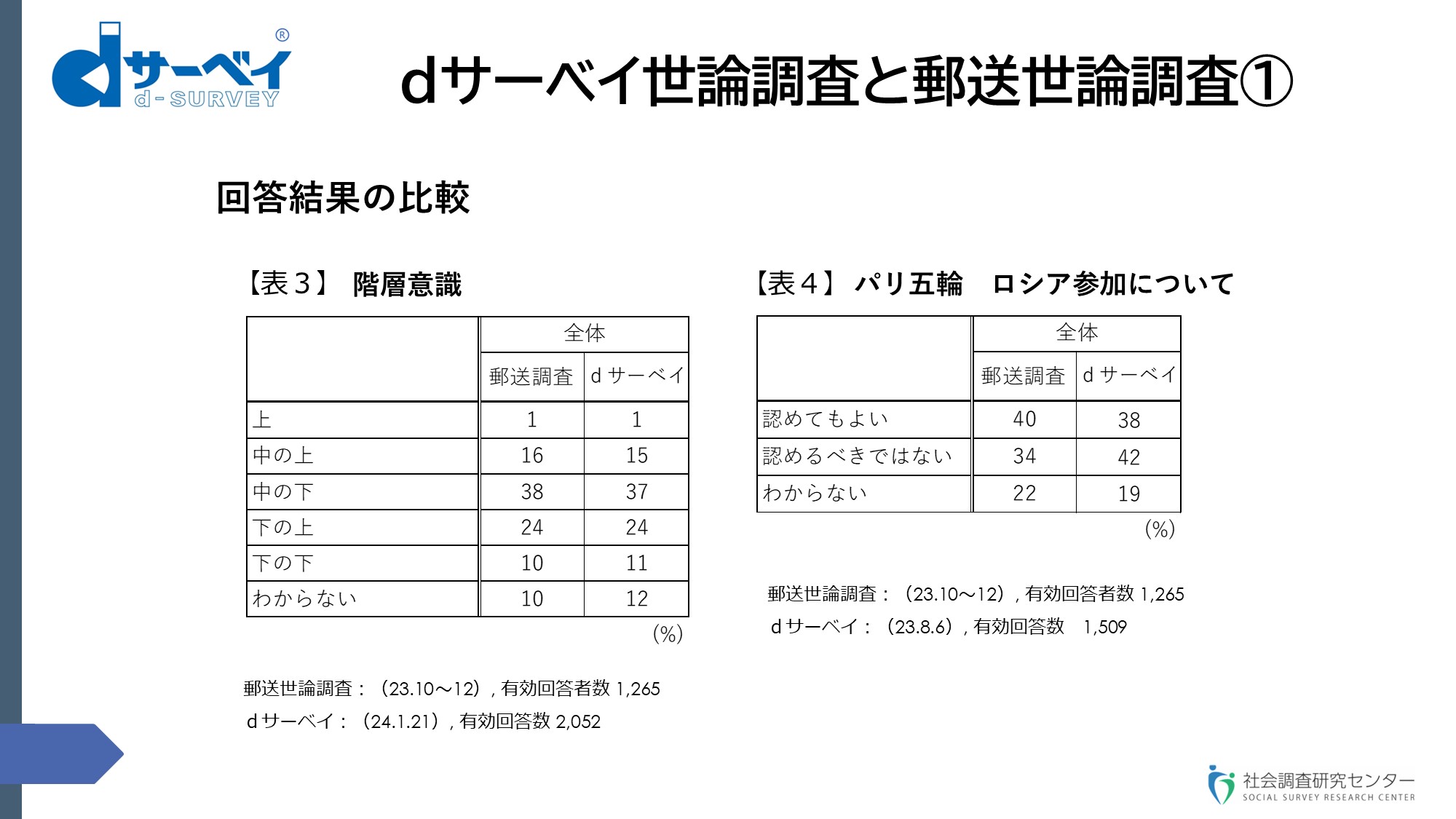
スライド⑯
左の【表3】を一番注目していただきたいのですけれども、いわゆる階層意識調査で、自分自身がどれに入るかを評定していただく。昨年の10月~12月の全国郵送調査で聞いた結果、「下の下」だと自分を評価された方が初めて1割になったので、私どもは非常にびっくりしたのですけれども、それを受けて、その直後にdサーベイでも全く同じ質問をしてみた場合、やはり1割を超えました。ああ、そうなのかなということで確認した次第です。
右の【表4】は昨年の10月とか8月ですので、今年の7月のパリ五輪について、1年近く前に聞いた結果ですけれども、パリ五輪にロシアの選手が参加するのを認めてもよいか、認めてはいけないかと。回答比率や順序はちょっと違うのですけれども、何を見ていただきたいかというと、「わからない」という回答の比率で、こういう非常に不確定な質問で、なおかつ自分の身の上に直接関わらない質問に関しては、「わからない」という回答が2割くらいに及ぶというのが一番ノーマルなのかなと思っています。
もう一つだけお見せします。スライド⑰(dサーベイ世論調査と郵送世論調査②)は、地球温暖化が与える影響に関して、深刻と思うか・思わないか【表5】。それから、地球温暖化対策に関してどの程度取り組んでいますか【表6】という結果です。回答の順位、大小関係、各回答の比率も近似しているので、dサーベイこそ、口幅ったいのですけれども、世論調査にふさわしいのではないかと私どもは思っています。

スライド⑰
最後のまとめに入らせていただきます。この後の討論にも関わるのですけれども、「世論調査のルールチェンジ」ということで、論点を整理すると、3つの基準で考えていく必要があるのではないか。
スライド⑱(世論調査のルールチェンジ)
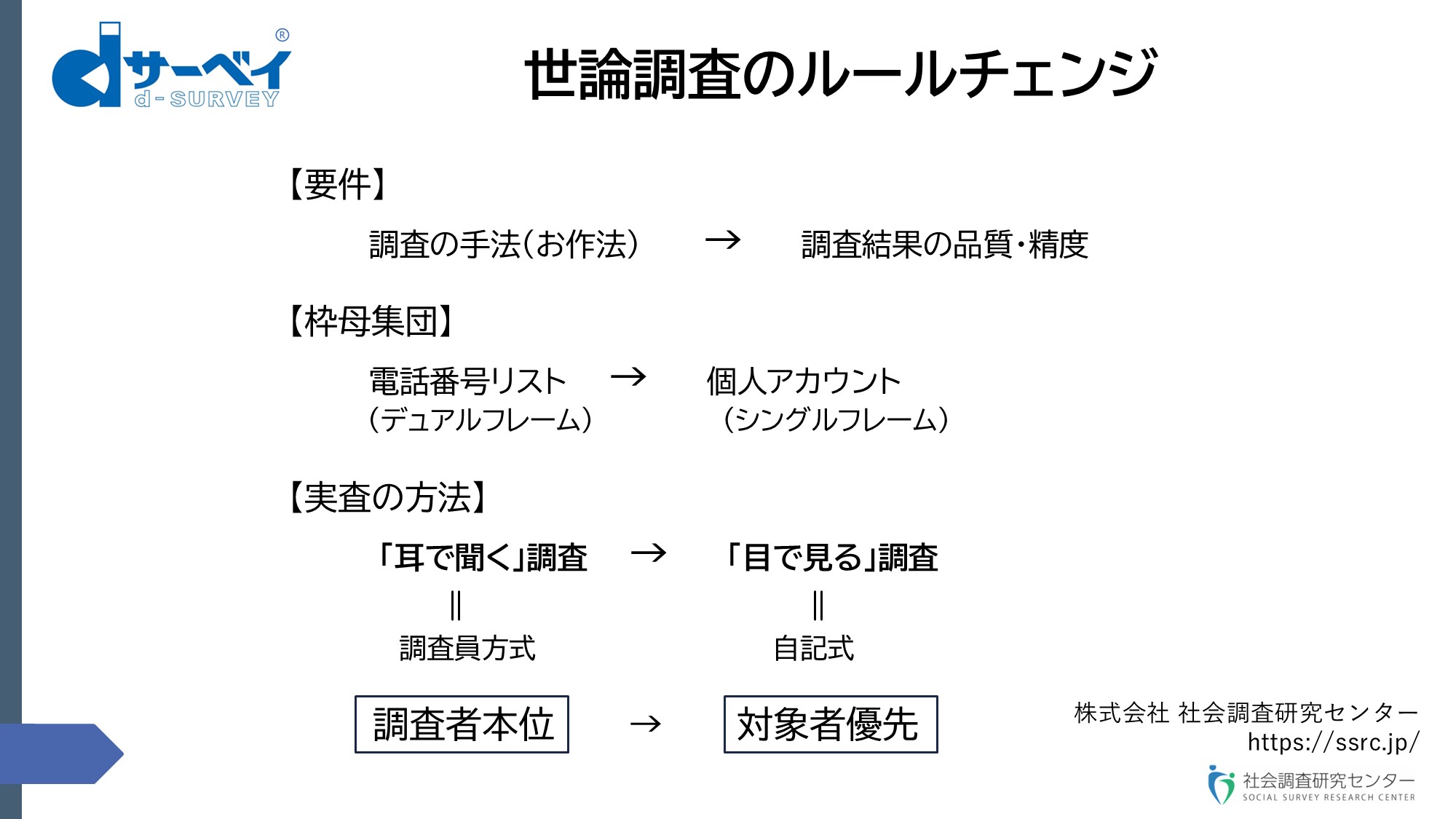
スライド⑱
世論調査の要件ですけれども、何が世論調査のカテゴリーに入るのか。世論調査なのか、そうではないのか。現在見ていると、調査の手法、それもお作法というのでしょうか、お作法どおりに調査を実施しているかどうか、これが非常に優先して捉えられている。そのお作法も、運用の方法とかに違いが結構あるのではないかなと思うのですけれども、残念ながらそこのところが開示されていないので、よく分かりません。
そういう、言ってみれば外形的な基準というものでしょうか、これを説明するだけでいつまで世間が世論調査の結果というのを信じてくれるのかなと若干不安になります。そこに関して言うと、調査結果の品質とか精度というものをきちんと示す必要がある。こちらに比重を移すべきではないかなと思います。
それから、2番目の枠母集団です。これは、今のRDDのミックスモードの場合はデュアルフレームです。しかも、固定電話番号と携帯電話番号のデュアルフレームですけれども、固定電話番号は、皆さんご存じのとおり世帯単位で、携帯電話番号は、それに対して個人単位で、しかも同一人が複数保持している、こういうフレームでサンプリングが行われる。我々のdサーベイに関しては、当然、何度も言いましたようにシングルフレームで、こちらのほうがカバレッジがいいのではないかと思います。
そして、最後ですけれども、先ほど述べたように、調査員が介在する・介在しないという、ここがポイントですよということでいうと、「耳で聞く」調査、「目で見る」調査との違いです。この違いは、一つには調査員方式か回答者本位かという点です。要するに、調査員方式というのは、調査員が回答をつくるということで、これまでの世論調査というのは、調査する側の都合とか理屈というのが優先している。それを、対象者のことをケアした方法に変える必要があるのではないか。少なくとも、今の社会のライフスタイルやコミュニケーションの変容に合わせて、世の中で許容される方法で実施していかなければ、メディアの実施する世論調査は、私は何度も言っているように、社会の公共財だと思いますけれども、その公共財として継続していくというのがかなり困難になっていくのではないかと思います。
私の報告は以上です。
ご清聴ありがとうございました。
2024年8月23日
社会調査研究センター 調査研究発表会